LABO
2020.10.28 SEO
構造化マークアップとは?
構造化マークアップとは?構造化データの種類、記述方法、リッチリザルトは SEO 対策に有効なのかを探ってみた。
構造化マークアップってなに?
構造化マークアップとは、HTMLで記述されている情報を、コンピューター(検索エンジン)に、何について記述されているのか、テキストの意味をより正確に理解してもらうための手法のことです。
コンピューターは、テキスト情報であることは認識が出来ても、「会社名」「電話番号」など、情報のひとつひとつの意味を細かく認識することが難しいため、
一定のルールに従って単語の意味をタグ付けする「構造化」をすることでコンピュータにも理解させようというのが「構造化マークアップ」です。
構造化データ(HTMLで書かれた情報を検索エンジンに理解しやすいようにタグづけしたもの)をマークアップすることによって、コンピューターがコンテンツ内容を認識しやすくなります。
さらに、リッチリザルトを検索結果に表示させることができる等のメリットもあります。
リッチリザルト(リッチスニペット)
リッチリザルトに少し触れておきたいと思います。
以前は「リッチスニペット」、「リッチカード」、「エンリッチ検索結果」など、種類によって呼び名が分かれていました。
現在では、Google が正式に「リッチリザルト」という名称に統一しています。
通常、検索結果の表示画面には Web ページのタイトルとページ内容等のテキスト情報(スニペット)が表示されますが、リッチリザルトは、パンくずリストや、画像、求人情報など、多くの情報を付加表示することができます。
しかし、設定すればリッチリザルトが必ず表示されるものではありません。サイトと関連性が無い情報の構造化データをマークアップしてしまうと、Google 側からガイドライン違反とみなされる「手動による対策」を受ける可能性もあるので注意が必要です。
参考サイト : 構造化データに関する一般的なガイドライン
リッチリザルトテストという、実装した構造化データが対応しているかを確認できるツールもあります。
使い方も簡単で、テストする URL を入力するか、コードを貼り付けるかで検証することができます。
参考サイト : リッチリザルトテスト
リッチリザルトと混合されやすいのですが、検索結果の表示画面には、ナレッジグラフ(PC でページの右側に表示されている、検索キーワードに関連した情報をまとめて表示しているもの)や 強調スニペット(自然検索内の Web ページから抽出して Google 検索結果の上部に強調表示されているもの)などもあります。
リッチリザルトの種類(2020.10.28 wed 現在)
リッチリザルトの種類の数は、だんだん増えていますが、 記事、パンくずリスト、イベント、Q&A、レシピ、求人情報など、現在は 30 種類ありました。 詳しい種類は下記の「Google 検索ギャラリー」で確認できます。
参考サイト : Google 検索ギャラリー
構造化マークアップによって SEO の順位が変動することはありませんが、リッチリザルトの表示は、通常の検索結果に加えてより多くの情報を付加表示できるので、
目立つようにすることでユーザーのアクセス数を増加させる効果はありそうです。
今までパンくずリストなど、何気なく使ってはいましたが、今回、自社サイトを使って詳しくみてみようと思います!
構造化データの設定について
まずは、構造化データの設定についてまとめてみました。
構造化マークアップは、「ボキャブラリー」と「シンタックス」で形式化しています。構造化データを記述するにはこの2つが必要になります。
ボキャブラリー
ボキャブラリーとは、構造化データを設定する際に、何についての情報なのか、モノゴトが持つ意味を表現するために定義された規格です。
「会社名」「住所」などのタグにあたる部分です。(住所だったら ”address” を記述することで、住所についての情報だということを検索エンジンに伝えます。)
ボキャブラリーにも様々なものがありますが、Google がサポートしている主なボキャブラリーは 「data-vocabulary.org(非推奨)」と 「schema.org(推奨)」です。
※ 2020 年 4 月 6 日以降からは、data-vocabulary.org マークアップは Google のリッチリザルト機能に対して無効になりました。 data-vocabulary.org マークアップは schema.org マークアップに置き換えなくてはいけないようです。
・schema.org(スキーマ)
schema.org とは、Google、Yahoo、Microsoft が共同で進めているボキャブラリーの規格で、より詳しい情報をコンピュータ(検索エンジン)に伝えるための記法です。 schema.org の仕様通りに、サイト内の HTML にマークアップする事ことで、リッチリザルトの表示や、コンピュータ(検索エンジン)に 1 つ 1 つの言葉の意味を細かく伝えることを可能にします。
schema.org はさまざまなボキャブラリーが定義されていて、構造化マークアップしたいコンテンツの種類によって選ぶことができます。
schema.org でマークアップする際にはタイプ(型)とプロパティ(属性)を指定します。
schema.org に定義されている単語の中からマークアップに適切な単語(タイプ)を探し出し、各タイプのページからさらに、別の単語(プロパティ)を使ってタイプを説明します。
マークアップする機会の多いものには、Organization(組織)、Place(場所)、Person(人)などがあります。
例えば、Organization(組織)のタイプに割り当てることができるプロパティは https://schema.org/Organization に記載されています。
それを見ると、name(名前)、address(住所)、telephone (電話番号)などのプロパティがありますので、これらのうちマークアップできるものを構造化していきます。
schema.org のタイプの一覧は下記の「Full Hierarchy」を参考にしてください。
参考サイト : schema.org「Full Hierarchy」
schema.org は、HTTP 版 (http://schema.org/) と HTTPS 版 (https://schema.org/) のどちらも使うことができますが、構造化データとして schema.org を使用するときの宣言は、HTTP 版が標準になります。
シンタックス
シンタックスとは、実際に構造化データを設定するための記述方法のことです。
構造化マークアップは HTML に記述します。その記述の仕方がシンタックスにあたります。
schema.org で定義されてる複数のボキャブラリーから選択して、用途に合わせながらマークアップします。
(このシンタックスに基づいてボキャブラリーをデータに紐付けることでデータの構造化が可能になります。)
シンタックスは主に「JSON-LD(Google 推奨)」「microdata」「RDFa」といった書き方があり、schema.org は、この 3 つのシンタックスを公式にサポートしています。
それぞれのシンタックスについても見てみましょう。
・JSON-LD(ジェイソンエルディー)
JSON-LD の「JSON」は「JavaScript Object Notation」(ジャバスクリプト・オブジェクト・ノーテーション)の略。LDは「Linked Data」(リンクト・データ)の略になります。
JSON-LD とは、構造化データを記述する際に使用するシンタックスです。Google が利用を推奨し、さらに W3C(Web 技術の標準化を行う非営利団体)の勧告もされています。
構造化データにしたい部分に直接記述する microdata や RDFa に比べて、JSON-LD は、script タグを用いて HTML 内のどの部分にも構造化データを記述できるという特徴があり、
マークアップを 1 か所にまとめることができるので、管理面でも記述内容を整理しやすいというメリットがあります。
既存のコードを書き換えることなくマークアップできるので、誤って既存のコードを書き換えてしまう失敗も回避できます。
デメリットとしては、表示されるテキストと別の場所に記述するため、更新漏れの注意が必要なことです。
HTML 内のコンテンツを変更する際、JSON-LD も変更する必要があり、更新漏れがあると実際の HTML の内容と構造化データの内容が一致しなくなってしまいます。
・Microdata(マイクロデータ)
限定的な環境でのみマークアップが可能なシンタックスです。
HTML の構造化データにしたい部分に直接記述します。
更新の際、目に入るので変更漏れは少なくなりますが、1 か所での管理ではないため更新に多少の手間がかかりそうです。
HTML5 でのみマークアップ可能で、W3C の勧告は 2013 年 10 月で止まってしまっているため、今後使用を推奨できるシンタックスではありません。
・RDFa(アールディーエフエー)(RDFa Lite)
Microdata と同様で該当する場所に直接 HTML でマークアップする方法のシンタックスです。
RDFa Lite は RDFa をもっと使いやすく簡素化したものです。
これも 1 か所での管理ではないため、更新に多少の手間がかかりそうですが、更新時の変更漏れは少なくなりそうです。
マークアップの仕方は microdata と似ていますが、HTML5 のみのような制限がなく、広い言語でマークアップ可能です。W3C の勧告もされています。
上記で述べたように、構造化データにおけるボキャブラリー(タイプとプロパティ)は、マークアップする物事を定義するもの、シンタックスはそのマークアップの記述方式のことです。 この 2 つを組み合わせて、構造化を行うことができます。
次は記述方法についてみていきたいと思います。
構造化データの記述方法
構造化データマークアップの実装には 2 種類の方法があります。
・HTML で schema.org の規格に従い直接マークアップする方法。
・構造化データマークアップ支援ツールを使用する方法
今回は HTML に直接記述する方法でみてみようと思います。
ボキャブラリーには schema.org、シンタックスに JSON-LD を使用します。
① schema.org のプロパティーを選びましょう!
まず、schema.org のプロパティーの選びます。
下記の schema.org のサイトにアクセスし、一覧から該当するタイプを選びます。
参考サイト : schema.org「Full Hierarchy」
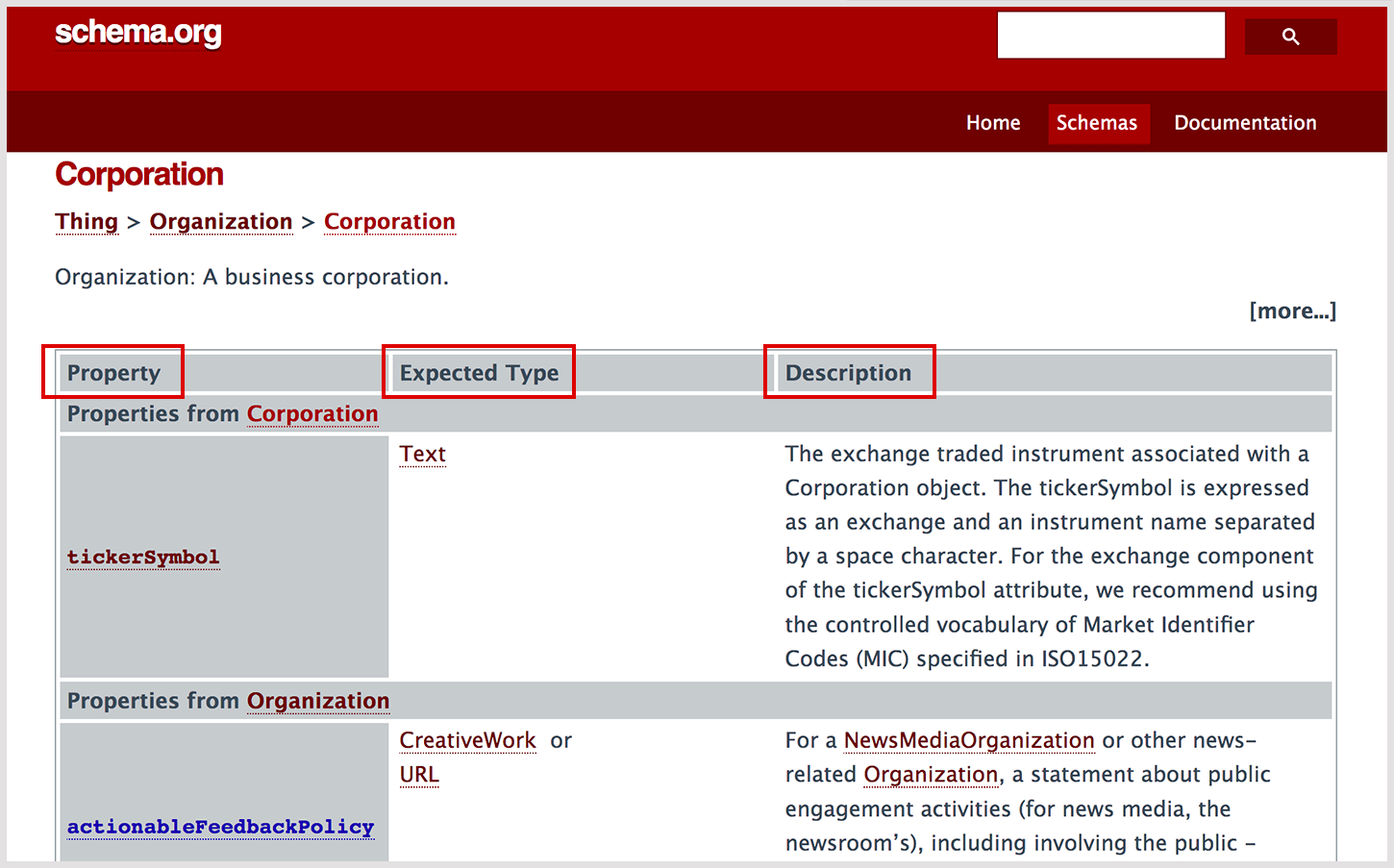
組織階層の企業「Corporation」をマークアップするとします。階層構造になっているので、これより下の階層に該当するものがないかを確認します。
「Corporation」をクリックすると https://schema.org/Corporation のページへ。
「Corporation」で扱えるプロパティーが一覧で表になっています。
表は、左から Property(プロパティ)、Expected Type(指定可能な種類・型)、Description(プロパティの説明)の順に並んでいます。
例えば Property(プロパティ)の「name」を見ると、 Expected Type(指定可能な種類・型)は「Text 型」で指定可能です。(Description(プロパティの説明)は会社の名前になります。)
② JSON-LD でマークアップしてみよう!
プロパティー選びの次は、JSON-LD を使った記述方法についてです。
JSON-LD の記述はブラウザに表示されることがありませんので、head 内や、body 内など HTML 内のどの部分に記述しても構いませんが、一般的には head 要素内に記述されます。
<script type="application/ld+json">
{
}
</script>
script
まず script タグを使って、JSON-LD の記述範囲を示します。
JSON-LD の 1 つのまとまりは、<script type="application/ld+json"></script>で囲みます。
script タグとなっていますが、Javascript などが実行されるわけではなく、JSON-LD を使う際の決まりです。
{ } (波括弧)
{ } で囲んだ 1 つのまとまりを JSON オブジェクトと言い、schema.org で表現する 1 つのモノは 「{」で始まり「}」で閉じます。
記述例として、次の会社情報を schema.org と JSON-LD を用いて表現してみます。
会社名: 株式会社ワンズクエスト
電話番号: 0467-82-9771
URL: https://www.ones-quest.co.jp/
「Corporation」(企業)のタイプは、 https://schema.org/Corporation で定義されています。
会社名には「name」プロパティ、電話番号には「telephone」プロパティ、サイト URL には「url」プロパティをそれぞれ割り当ると次のようになります。
<script type="application/ld+json">
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "株式会社ワンズクエスト",
"telephone": "+81-467-82-9771",
"url": "https://www.ones-quest.co.jp/"
}
</script>
「:」(コロン)、
「"」(ダブルクォーテーション)、
「,」(カンマ)
JSON オブジェクトは、1 つまたは複数の Key(属性)と Value(値)のペアで構成されます。
左側に Key(この場合「name」など)、右側に Value (この場合「株式会社ワンズクエスト」など)を記述し、それぞれを「"」(ダブルクォーテーション)で囲みます。
Key と Value の間は「:」(コロン)で区切り、ペアを増やす場合は「,」(カンマ)を必ず入れます。
最後のペアの場合はカンマは入れません。(忘れやすいので注意が必要です。)
@context
Key の中でも、@context は良く使われます。@Context は構造化データがどのような定義(ボキャブラリー)に基づくかを指定します。
@context の Value は基本的に「http://schema.org」を指定し、http://schema.org での定義に従って構造化データを記述することを宣言します。
@type
@type も Key の中で良く使われます。@type は何について表現するのかを指定します。schema.org で定義されているモノ(タイプ)が Value になります。
@type で、Corporation を指定すれば、企業について表現することができ、企業に関する具体的な情報を、構造化データで記述できるようになります。
@type 以降は、@type の Value で指定したタイプで利用できるプロパティを記述していきます。どんなプロパティが利用できるのかは、schema.org のサイトで確認します。
上記の場合、プロパティは 「https://schema.org/Corporation」 内で定義されているものであれば、どれでも記述できます。1 行ずつ記述していき、順不同で構いません。
上記では「name」や「telephone」、「URL」を記述して、各コンテンツの具体的な情報を増やしています。
「telephone」の電話番号については国番号の指定が必要です。日本なら「+81」。記述例 +81-467-82-9771(0467-82-9771)となります。
Embedding(エンベッディング)
Embedding についても触れておきたいと思います。
value にさらに JSON オブジェクトを埋め込むことを Embedding と言います。(embed は Embedding の略です。)
企業情報に「address」を Embedding してみましょう。
「https://schema.org/Corporation」の「address」プロパティは「Text」と「PostalAddress」タイプがあり、
「Text」は単純な文字情報なので、「PostalAddress」を指定します。「PostalAddress」は「https://schema.org/PostalAddress」内で定義されています。
書き方は、埋め込みたい key の value に { } を記述し、タイプを指定したら、必要な key と value のペアを記述します。
「address」プロパティが key、「PostalAddress」タイプの JSON オブジェクトが value となります。
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "株式会社ワンズクエスト",
"address": {
"@type": "PostalAddress",
"postalCode": "253-0055",
"addressRegion": "神奈川県",
"addressLocality": "茅ヶ崎市",
"streetAddress": "中海岸1-7-11 三橋ビル2F",
"addressCountry": "JP"
},
"telephone": "+81-467-82-9771",
"url": "https://www.ones-quest.co.jp/"
}
Array(アレイ)
value に複数の値を指定する場合は、Array(配列)を使用ます。
Array は、[ ](角カッコ)でくくり、値は「,」(カンマ)で区切ります。さらにそれぞれの value を「"」で囲みます。
これで、value に複数指定することができます。
上記の企業情報に、複数の関連するサイトや SNS の URL を記載するプロパティ「sameAs」を指定してみましょう。
{
"@context": "http://schema.org",
"@type": "Corporation",
"name": "株式会社ワンズクエスト",
"address": {
"@type": "PostalAddress",
"postalCode": "253-0055",
"addressRegion": "神奈川県",
"addressLocality": "茅ヶ崎市",
"streetAddress": "中海岸1-7-11 三橋ビル2F",
"addressCountry": "JP"
},
"telephone": "+81-467-82-9771",
"url": "https://www.ones-quest.co.jp/",
"sameAs": [ "https://twitter.com/odekaken",
"https://www.facebook.com/odekaken/"
]
}
Array を Embedding でも使うことができます。
記述については、パンくずリストやよくある質問(FAQ)のマークアップ設定時に確認してみましょう!
次回は、構造化データの確認に便利な「リッチリザルトテスト」の紹介も含め、実際に自社サイトに設定し、検証してみたいと思います。
